SLI’s and SLO’s, how to wrap your head around it and actually use them to calculate availability
After reading the chapter of Google SRE Workbook about implementing SLO’s I was kind of confused. It was difficult to find some sense in this SLI, SLO, SLA word soup, so here I will try to give one of the explanations of what is actually SLI and SLO and how to implement and use them with Prometheus and Jsonnet.
SLI
It’s easier to think about SLI (Service Level Indicator) as a combination of two things: metric (95th percentile of response time or health status) and threshold (what is considered as available or not for this particular metric).
Let’s imagine that you have a bunch of services running on different namespaces in k8s, each of them has a /health endpoint that returns returns “healthy” or “unhealthy” string as a response. Then your ingress controller knows how to call this endpoint and write metrics for health and also response time for all requests.
Health metrics can look like this:
service_health{status="healthy",server="858b678dd8-f2vc6", namespace="dev",service="my-service"} 1service_health{status="unhealthy",server="858b678dd8-f2vc6", namespace="dev",service="my-service"} 0
And standard bucketed response metrics for response time:
service_http_request_endpoint_bucket{route="/API/MYENDPOINT",server="858b678dd8-f2vc6",namespace="dev",service="my-service",le="100"} 3Having those metrics in place we can build a simple predicate, where the left part is the metric of our SLI, the right part is the threshold and the result tells us for each moment in time if our service was available or not:
1) service_health{status=”healthy”} > 02) histogram_quantile(0.95, sum by(namespace, service, le) (rate(service_http_request_endpoint_bucket{route=”/API/MYENDPOINT”,service=”my-service”}[5m]))) < 100ms
So we can say that SLI is basically something that tells us for each moment of time:
- If the 95th percentile of /API/MYENDPOINT endpoint for the last 5m was under 100ms, service is available
- If the service health metric with the healthy label is greater than 0, service is available
SLO
When you have your SLI, you know for each moment of time if your service was available. Then you can aggregate this data over any period of time, say 4 weeks, and calculate the percentage of time that your service was available in that period. Let’s say you calculated that number to be 99.5 over the last 4 weeks. SLO (Service Level Objective) would be your target for that number (you want that number to be 99.99).
Calculating SLI
Now, when we know what is what in this soup, we can try to build a small framework to measure our availability. We’ll try to do it using plain Jsonnet without any libraries. You can find a full example in the GitHub repo.
First, we’ll need to teach our framework to produce Prometheus recording rules:

Then we’ll need functions to record our SLI for each moment in time (the metric that will consist only of 0 or 1, where 1 means available and 0 is not available). These methods accept the name of your SLI as a parameter, so we’ll have only one metric that will produce a series per namespace, service, and SLI name.

As you can see we will record a new metric named service:sli:conformity:status, which is produced by comparing our SLI metric to the SLI threshold and will reflect our service availability at each point in time. The resulting metric will look like this:
service:sli:conformity:status{name="health", namespace="dev", service="my-service"} 1
service:sli:conformity:status{name="latency:myendpoint:95:100:ms", namespace="dev", service="my-service"} 1Next, we’ll need a function to clean up our series from bad values. We need only to know simple 0 or 1 for availability, but our SLI metrics can produce for example NaN if our endpoint wasn’t called recently, so we need to remove NaN’s before we start aggregating the results.

Next, we need the rule to record our SLI metric:
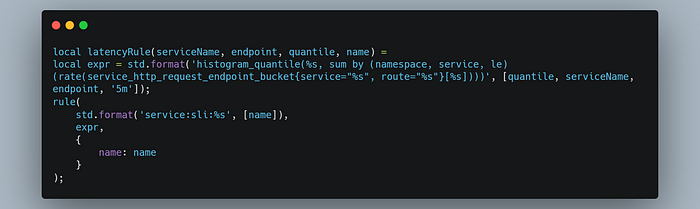
And finally, merge all this into SLI calculation:

The name variable will hold the SLI name which then will be stored as the label of SLI metrics that we’ll create.
This will produce rules that will record our metric, then record that metric cleaned from unwanted values, and finally record our SLI. Which we can then aggregate overtime to get availability percent (using Prometheus avg_over_time function and having only 0 and 1 in metric we can easily calculate the percentage), record our availability and display it in the Grafana dashboard:

Once you can track your SLI’s, you can set your targets in the appropriate SLO’s and move on into a beautiful world of error budgets :)
You can find a full example with both latency and health SLI’s in the GitHub repo.
